Rancher CLI kan gedownload worden vanuit de Rancher UI, via het menu linksboven en dan onderaan ‘About’ waar de links staan

Uitpakken en installeren en via de command line is er dan een ‘rancher‘ binary beschikbaar.
Lees verder
Rancher CLI kan gedownload worden vanuit de Rancher UI, via het menu linksboven en dan onderaan ‘About’ waar de links staan
Uitpakken en installeren en via de command line is er dan een ‘rancher‘ binary beschikbaar.
Lees verderOm niet elke keer bij het toevoegen van een repository in ArgoCD de credentials op te moeten geven, is het handig om Repository Credentials toe te voegen. Doe je dit bijvoorbeeld voor een groep genaamd ‘argocd’ dan hoef je geen credentials meer op te geven bij het toevoegen van een repository in deze groep.
Op de commandline:
argocd repocreds add https://gitlab.com/argocd --username user --password password
Hierbij is het password bijvoorbeeld het ‘Impersonation token‘ van deze gebruiker die je via Admin -> Users -> de gebruiker -> Impersonation Tokens kunt zetten met (tenminste) ‘read_repository‘ rechten.
Repositories in deze groep kunnen dan toegevoegd worden met:
argocd repo add https://gitlab.com/argocd/voorbeeld.git
In onderstaand schema zie je als eerste een K8s configuratie die gebruik maakt van dockershim. In het schema daaronder staat een K8s configuratie zonder docker, maar met de CRI-containerd
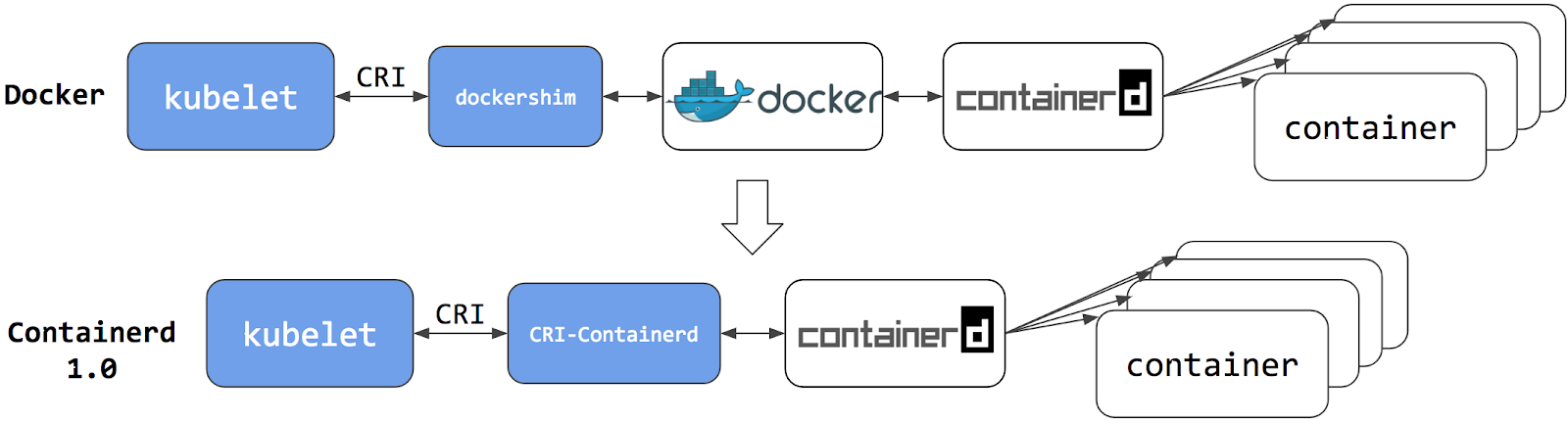
Dockershim is een shim waarmee de gehele docker engine gebruikt kan worden voor de container images. In Kubernetes release v1.24 is de dockershim verwijderd en wordt gebruik gemaakt van CRI-containerd. (of CRI-Dockerd)
Container images die gemaakt zijn met docker werken nog steeds prima met containerd en dus geen probleem voor images die reeds aanwezig zijn.
Lees verderOp een downstream K3s cluster kan de cattle-cluster-agent niet verbinden met de rancher-server. oorzaak is de DNS-record die niet gevonden kan worden. Een log van de pod geeft de volgende foutmelding:
ERROR: https://rancher.digitalinfo.nl/ping is not accessible (Could not resolve host: rancher.digitalinfo.nl)
Dit kan opgelost worden door de deployment aan te passen en er een dnsConfig in aan te passen. Deze wordt dan alsvolgt:
dnsConfig:
nameservers:
- 8.8.8.8
dnsPolicy: NoneHierna worden de Pods ververst en zal de rancher server gevonden worden via de Google DNS server (8.8.8.8). Voorwaarde is uiteraard wel dat je jouw rancher DNS-record geregistreerd hebt in een externe DNS server.
‘Ter lering ende vermaeck‘ wil ik in mijn on-premise Rancher Management clusters een Azure K8s cluster toevoegen. Om dat te doen is een ‘Cloud Credential‘ nodig voor Azure. Er zijn gratis trial subscriptions mogelijk voor Azure en daar maak ik dan ook gebruik van: https://azure.microsoft.com/nl-nl/free/
Lees verderBinnen Kubernetes bestaat de mogelijkheid om PVC’s aan te maken op NFS-shares. Dit kan door een PV aan te maken met type NFS, maar het kan ook dynamisch met een NFS Provisioner.
Gebruik Helm om de repo toe te voegen en installeer de NFS Provisioner met Helm.
Lees verderOp een NFS server (NAS, Storage Sever, etc..) worden NFS shares aangemaakt die via een NFS client gemount kunnen worden in een VM. Met Proxmox kunnen de NFS shares gemount worden op de pve en dan gebruikt worden als extra disk aan een VM. Op zich vrij eenvoudig, hier een beknopte uitleg.
Lees verderMaar er is altijd de Container Runtime Interface (CRI) die ervoor zorgt dat de images die gemaakt zijn met docker kunnen (blijven) werken in een Kubernetes cluster.
Dus, waar gaat dit dan over?
Lees verderVolgens https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/configure-cgroup-driver/ dient het aanbeveling om ‘systemd‘ te gebruiken als driver voor cgroups. Dit komt de stabiliteit van docker ten goede. Vóór Kubernetes versie 1.21 is de standaard nog om hier ‘cgroupfs’ voor te gebruiken maar aangezien kubeadm systemd gebruikt om kubelet aan te sturen is dit nu de nieuwe standaard en de default vanaf v1.21.
Lees verderDe efficientie van workloads worden voor een groot deel bepaald door de gebruikte resource-requests en resource-limits. Hoe dichter deze bij elkaar liggen, hoe efficienter de workload is. Het gevaar is echter dat met opstarten van een workload vaak meer CPU en memory gebruikt wordt en deze dient dan wel onder de resource-limit te blijven. Voor wat betreft memory-limit-overschrijding zal de pod opnieuw gestart worden door een Out-Of-Memory (OOM) event en overschrijding van het CPU-Limiet leidt tot CPU-trothling wat vertragingen in CPU time veroorzaakt. Voor beide limieten geldt uiteraard dat deze de Rancher-project resource-quota niet kan overschrijden en de node waarop de workload staat dient uiteraard de noodzakelijke CPU en Memory te kunnen leveren.

Via Proxmox (of VMWare) is een extra disk toegevoegd aan een VM. Deze disk is in de VM de tweede disk, dus ‘/dev/sdb‘ en deze is 100Gb. Nu willen we deze uitbreiden met 20Gb echter zonder downtime van de VM, met andere woorden: ‘on the fly’.

Binnen Proxmox kan de disk groter gemaakt worden, dus die maken we 120G met de ‘Disk Action -> + Resize’ in het ‘Hardware’ overzicht.
Lees verderMijn Raspberry Pi Kubernetes Cluster bestaat uit 3 nodes: 1 master (Control Plane en ETCD) en 2 workers. Een extra Raspberry Pi dient als Reverse-Proxy. Om in één oogopslag te zien welke Raspberry Pi welke role heeft, gebruik ik hiervoor de system-board LED’s.
Lees verder